 NDLOCR-Lite
NDLOCR-Lite
詳細情報
| タイトル | NDLOCR-Lite |
|---|---|
| URL | https://github.com/ndl-lab/ndlocr-lite |
| バージョン | ver 1.1.3 |
| 更新日 | 2026/03/14 |
| 追加日 | 2026/02/28 |
| 種別 | フリーソフト |
| 説明 | NDLOCRの軽量版を目指して開発されたOCR。 |
レビュー
概要
NDLOCR-Lite は、国立国会図書館(NDL)のNDLラボが開発・公開しているオープンソースの OCR(光学文字認識)ソフトウェアです。国立国会図書館が長年取り組んできた大規模OCRシステム「NDLOCR」の軽量版として位置づけられており、ノートパソコンなど一般的な家庭用 PC でも GPU なしで動作することを目指して設計されています。NDL 古典籍 OCR-Lite の開発経験を踏まえ、職員が内製で開発したもので、図書・雑誌などのデジタル化画像からテキストデータを生成することができます。Windows 11・macOS・Ubuntu 22.04 に対応しています。
主要な特徴・機能
- GPU 不要・軽量動作 – 一般的なノートパソコン等でも動作する軽量設計で、GPU がなくてもテキスト認識が可能
- 高精度レイアウト認識 – DEIMv2 を採用した最新のレイアウト解析により、複雑なページ構造にも対応
- 高精度文字列認識 – PARSeq を活用した文字認識モデルで、現代語・近代語の文字認識精度を向上
- 読み順整序 – 既存 NDLOCR のモジュールを活用し、日本語特有の縦書き・横書き混在ページの読み順を適切に整理
- デスクトップ GUI アプリ対応 – コマンドラインだけでなく GUI アプリとして利用可能(Python 3.10 以上が必要)
- クロスプラットフォーム – Windows 11・macOS・Ubuntu 22.04 に対応
- カスタマイズ可能 – モデルの差し替えや拡張を行いたい開発者向けの構造を提供
対象ユーザー
- 古書・雑誌・資料のデジタル化に取り組む図書館員・アーキビスト
- GPU を持たない一般ユーザーで、スキャン文書のテキスト化をしたい方
- 研究・学術目的で大量の紙資料をデジタルテキスト化する研究者
- OCR モデルをカスタマイズして独自の認識システムを構築したい開発者
ライセンス情報
CC BY 4.0(クリエイティブ・コモンズ 表示 4.0 国際)ライセンスで国立国会図書館が公開。著作権表示を行えば、商用・非商用を問わず自由に利用・改変・再配布が可能。依存ライブラリのライセンスは LICENCE_DEPENDENCIES ファイルで確認できる。
スクリーンショット
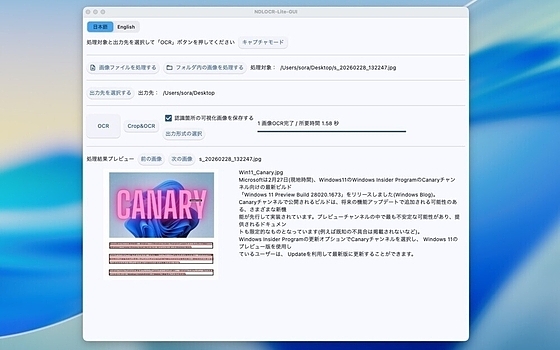
更新グラフ
バージョン履歴
これはプレビュー版です
#32 への対応とキャプチャモード及びクロップモードの修正
Full Changelog: 1.1.2...1.1.3
これは動作確認用のプレビュー版です。
What's Changed
- 画像入力周りの修正 by @ndl-lab-staff in #23
- .が複数含まれるファイル名への対応(cliのみ) by @ndl-lab-staff in #24
- perf: replace PIL with cv2 and optimize numpy operations in preprocessing by @ooki1jp in #25
Full Changelog: 1.1.1...1.1.2
これはプレビュー版です
#14
#15
#19
の修正検討
GUI版において、複数階層のディレクトリを再帰的に探索して画像を見つける機能を追加
#1
#3
#5
に修正対応しました。
What's Changed
- lxmlのバージョンアップ by @ndl-lab-staff in #6
- Intel Macで起動しない不具合を修正 by @ndl-lab-staff in #8
- Windowsにおいてまれにmain.pyが見つからなくなる不具合を修正 by @ndl-lab-staff in #11
Full Changelog: 1.0.0...1.1.0
お知らせ
Windowsにて起動時にPathNotFoundException が発生のように、特定のWindows環境において起動に失敗する事象が報告されています。
外部ライブラリの不具合とみられ、解決策を調査していますが、応急処置として、flet\ndlocr_lite_guiのように空ディレクトリを作成すると解消することが報告されています。